#install.packages("magrittr") # for piping %>%
#install.packages("ade4") # PCA computation
#install.packages("factoextra")# PCA visualization
library(psych)
#library(fmsb)
#PCA - principal component analysis
#Covid19 data analysis
mydata<- read.csv(file.choose())
summary(mydata)
#Define_mydataiables
#mydata<- cbind(CO1,CO2,CO3,CO4,CO5,CO6,CO7,CO8,PMO1,PMO2,PMO3,
#AT1,AT2,AT3,AT4,AT5,AT6,AT7,SN1,SN2,SN3,SN4,
#PBC1,PBC2,PBC3,PBC4)
#Calculating_Cronbach's Alpha
covid_concern<- alpha(data.frame(mydata[c("CO2", "CO3", "CO5", "CO7")]))
attitude<- alpha(data.frame(mydata[c("SN3", "PBC1", "PBC2")]))
social_norm<- alpha(data.frame(mydata[c("CO4", "AT7", "SN1", "SN2", "PMO1")]))
perc_beh_control<- alpha(data.frame(mydata[c("AT2", "AT4", "AT5", "AT6")]))
perc_mor_obligation<-alpha(data.frame(mydata[c("CO8", "AT1")]))
#KMO
covid_concern<- KMO(data.frame(mydata[c("CO2", "CO3", "CO5", "CO7")]))
attitude<- KMO(data.frame(mydata[c("SN3", "PBC1", "PBC2")]))
social_norm<- KMO(data.frame(mydata[c("CO4", "AT7", "SN1", "SN2", "PMO1")]))
perc_beh_control<- KMO(data.frame(mydata[c("AT2", "AT4", "AT5", "AT6")]))
perc_mor_obligation<-KMO(data.frame(mydata[c("CO8", "AT1")]))
#Bartlett's Test of Sphericity
#$pvalue is the sphericity(sig.) value
covid_concern<-cortest.bartlett(cor(data.frame(mydata[, 1:8])))
attitude<- cortest.bartlett(cor(data.frame(mydata[, 9:15])))
social_norm<- cortest.bartlett(cor(data.frame(mydata[, 16:19])))
perc_beh_control<- cortest.bartlett(cor(data.frame(mydata[, 20:23])))
perc_mor_obligation<-cortest.bartlett(cor(data.frame(mydata[c("CO8", "AT1")])))
#Descriptive statistics
summary(mydata)
cor(mydata)
#Principal Component Analysis
pca1<-princomp(mydata, scores=TRUE, cor=TRUE)
summary(pca1)
#Loading of principal components
loadings(pca1)
#pca1$loadings
#Scree plot of eigenvalues
plot(pca1)
#barplot(pca1)
screeplot(pca1, type="line", main="Scree Plot")
#Biplot of score mydataiables
biplot(pca1)
#Scores of the components
pca1$scores[1:26, ]
#Rotation
#mydataimax(pca1$roatation)
#Promax(pca1$rotation)
#Factor analysis - different results from other softwares and no roation
fa1<- factanal(mydata, factor = 5)
fa1
fa2<- factanal(mydata, factor=5, rotation="varimax", scores = "regression")
fa2
fa3<- factanal(mydata, factors=5, rotation = "cluster", scores = "regression")
fa3
library(ade4)
library(factoextra)
library(magrittr)
#Visualize eigenvalues (scree plot). Show the percentage of variances explained by each principal component.
fviz_eig(pca1)
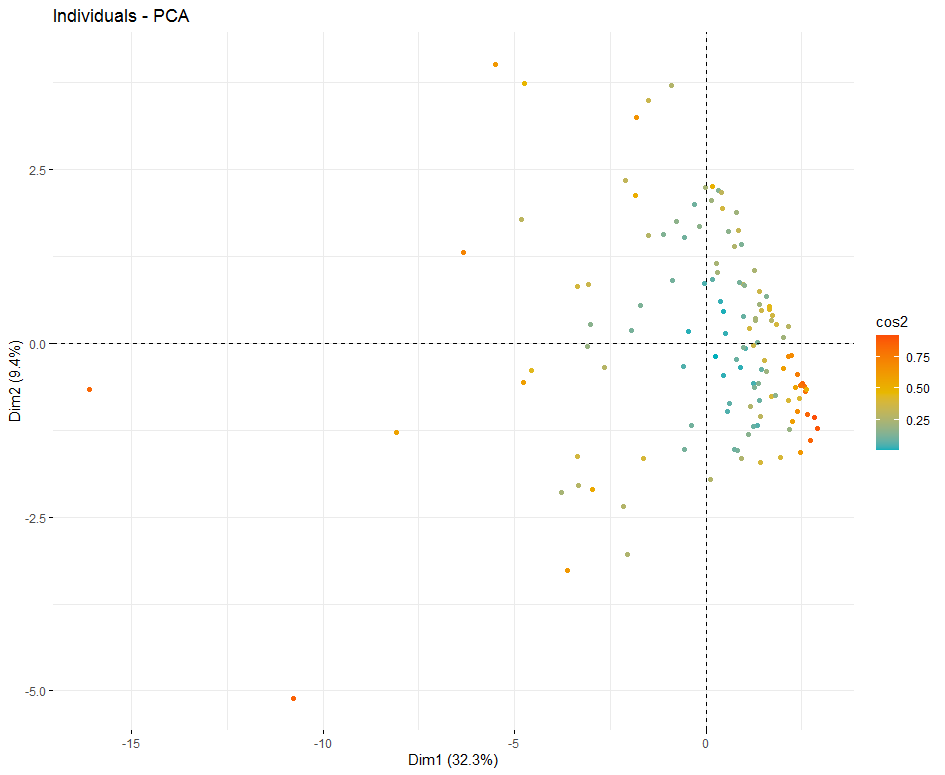
#Graph of individuals. Individuals with a similar profile are grouped together.
fviz_pca_ind(pca1,
col.ind = "cos2", # Color by the quality of representation
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE) # Avoid text overlapping
#Graph of variables. Positive correlated variables point to the same side of the plot. Negative correlated variables point to opposite sides of the graph.
fviz_pca_var(pca1,
col.var = "contrib", # Color by contributions to the PC
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE # Avoid text overlapping
)
#Biplot of individuals and variables
fviz_pca_biplot(pca1, repel = TRUE,
col.var = "#2E9FDF", # Variables color
col.ind = "#696969" # Individuals color
)
#The ade4 package creates R base plots.
# Scree plot
screeplot(pca1, main = "Screeplot - Eigenvalues", xlab="Component")
# Correlation circle of variables
s.corcircle(pca1$co)